You need DATA?
Crafting Exceptional Web Crawlers
Let Us Handle the Data Grunt Work While You Focus on Value Creation
Get a quote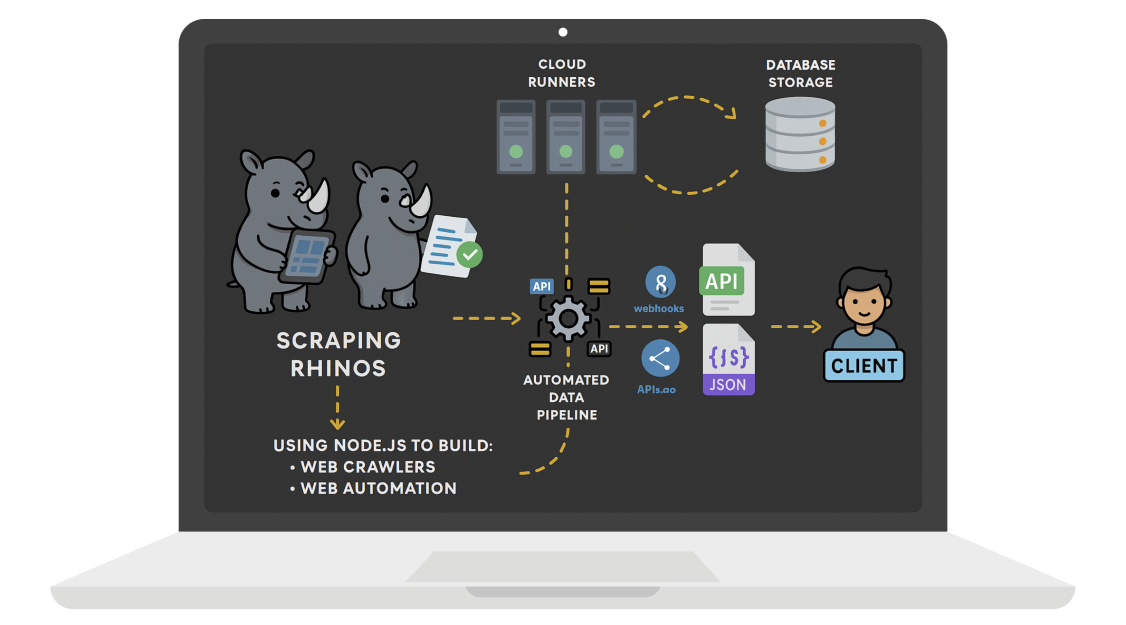
Let Us Handle the Data Grunt Work While You Focus on Value Creation
Get a quote
Power your platform with structured, interlinked data across Races, Events, and Organizers. Our JSON-based APIs are ideal for race directories, aggregator sites, and calendar platforms.
The base layer: includes event name, long/short descriptions, date, location, media assets, external links, and metadata.
Every _id here becomes the race_id in our Events API.
{
"_id": "race123",
"name": "Chase The Sun Tatton 10k",
"description": "Chase the sun and experience...",
"description_short": "Chase the sun as it goes down...",
"date": "2025-05-20",
"location": { "country": "UK" },
"media": {
"main_pic": "https://...",
"additional_pic_01": "https://..."
},
"links": ["https://eventsite.com"],
"scraper": {
"type": "new",
"url": "https://...",
"datetime": "2025-05-10T12:00:00Z"
},
"meta": { "owner": "", "owner_collection": "" }
}
Each event is directly linked to a race via race_id. You also get distance, cost, start time, and scraping metadata.
{
"_id": "event456",
"name": "Evening 10k Run",
"description": "Chase the sun as it goes down...",
"distance": "10km",
"cost": "\u00a325",
"start_time": "6:00 PM",
"race_id": "race123",
"scraper": {
"type": "new",
"url": "https://..."
},
"meta": { "owner": "", "owner_collection": "" }
}
Organizer data includes name, sanitized description, verified contact info, and original website. Events are associated with organizers implicitly via scraper metadata.
{
"_id": "org789",
"name": "UK XYZ Club",
"description": "Leading club organizing sunset races across the UK.",
"email": "info@xyz.com",
"phone": "+44 123 456 789",
"website": "https://ukrunclub.com",
"scraper": {
"url": "https://xyzclub.com",
"datetime": "2025-05-10T12:00:00Z"
}
}
Relationships:
Races contain event-level metadata and are the parent to Events.Events include race_id for race linkage.Organizers are connected via scraper metadata and collection ownership.

Uniquely Stealthy Web Crawlers, Evading Detection Effortlessly.

Advanced scraping tools coupled with robust pipelines.

Comprehensive full-stack web development services encompassing architecture, planning, implementation, QA, and ongoing support.
Experience unmatched stealth with our advanced web scraping solutions. Utilizing residential IPs, we operate undetectably. We effortlessly navigate past a multitude of anti-crawler measures including captchas, Recaptcha, hcaptcha, and Cloudflare turnstile. Additionally, our custom tooling ensures seamless evasion of TLS and browser fingerprinting, safeguarding your data acquisition endeavors.
Get A Quote


Experience seamless data solutions with our tailored services: Custom web scraping software developed using JavaScript and Node.js. Receive sanitized datasets in SQL, Excel, CSV, or JSON formats. Access high-availability data pipelines, such as AWS SQS instances linked to Big Data NoSQL databases like DynamoDB. Simplify management with our intuitive web app and dashboard, facilitating easy execution and oversight of web crawlers and data pipelines.
Get A Quote
Unlock the full potential of your web projects with our top-tier full-stack development services. From initial architecture and planning to final implementation, rigorous QA, and ongoing support, we're with you every step of the way, ensuring seamless execution and success.
Get A Quote

